This is Ge Li (Bruce), 李戈
 I am a researcher in machine learning and robotics at the Karlsruhe Institute of Technology (KIT), Germany. My supervisors are Prof. Gerhard Neumann and
Prof. Rudolf Lioutikov.
I am a researcher in machine learning and robotics at the Karlsruhe Institute of Technology (KIT), Germany. My supervisors are Prof. Gerhard Neumann and
Prof. Rudolf Lioutikov.
I focus on advancing the learning and representation of robotic motion policies, with a particular emphasis on their applications in imitation and reinforcement learning. I aim to improve model capacity, learning efficiency, and interpretability by leveraging state-of-the-art algorithms and tools.
In addition to my research, I serve as a teaching assistant at KIT, contributing to courses Cognitive Systems, Machine Learning, and Deep Reinforcement Learning. I also mentor several Bachelor and Master students for their research projects and theses.
Education & Experience
2020 - 2025, Karlsruhe Institute of Technology, Germany, Doctor’s Degree, Computer Science.
2015 - 2019, RWTH Aachen University, Germany, Master’s Degree, Computer-Aided Mechanical Engineering.
2011 - 2015, University of Science and Technology of China, Bachelor’s Degree, Mechanical Engineering.
2018 - 2019, Max Planck Institute for Intelligent Systems, Germany, Robot Research Intern.
2018, Alfred Kärcher SE & Co. KG, Germany, Robot Software Engineer Intern.
News
Nov. 2025, I have successfully passed my PhD defense and will get my Doctor’s degree 🎉.
Sept. 2025, two co-authored papers got accepted by NeurIPS 2025 🇺🇸.
August 2025, one co-authored paper got accepted by IEEE-RAL 2025.
August 2025, one co-authored paper got accepted by CoRL 2025 🇰🇷.
May 2025, one co-authored paper got accepted by ICML 2025 🇨🇦.
Jan. 2025, my latest work got accepted by ICLR 2025 as a Spotlight paper🔥. I presented it in Singapore 🇸🇬.
Dec. 2024, I presented my co-authored work in NeurIPS 2024 in Vancouver, Canada 🇨🇦.
Aug. 2024, one co-authored paper got accepted by CoRL 2024 🇩🇪.
May 2024, I presented my PhD work in ICLR 2024 in Vienna, Austria 🇦🇹.
Publications
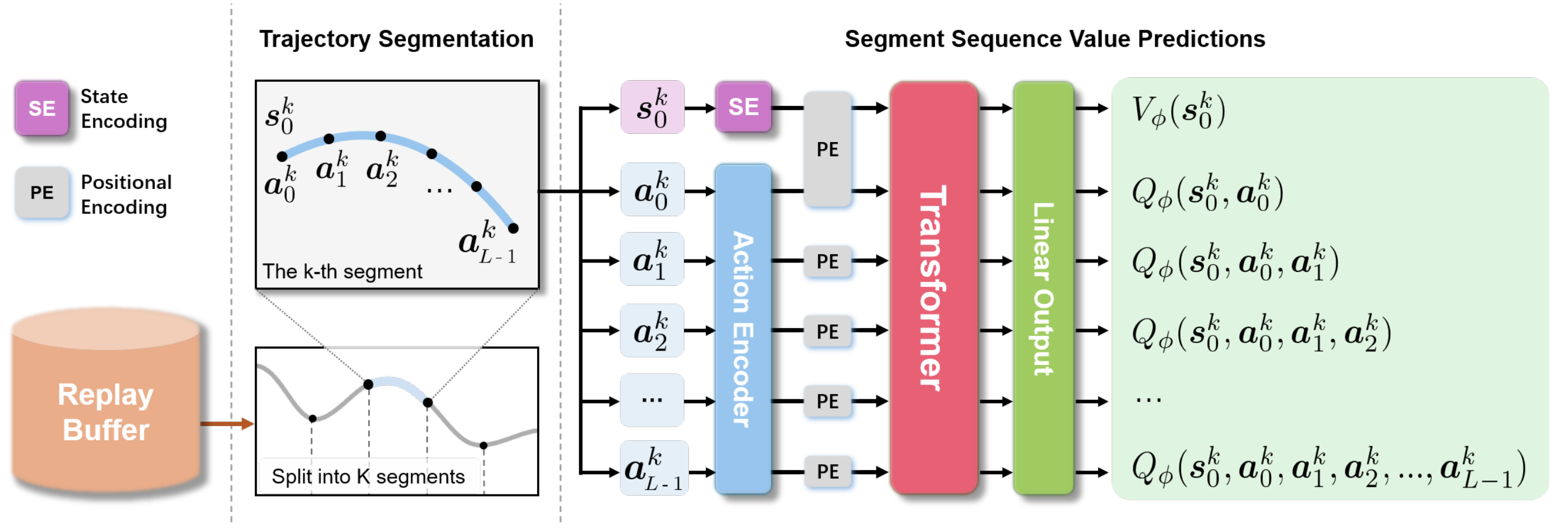
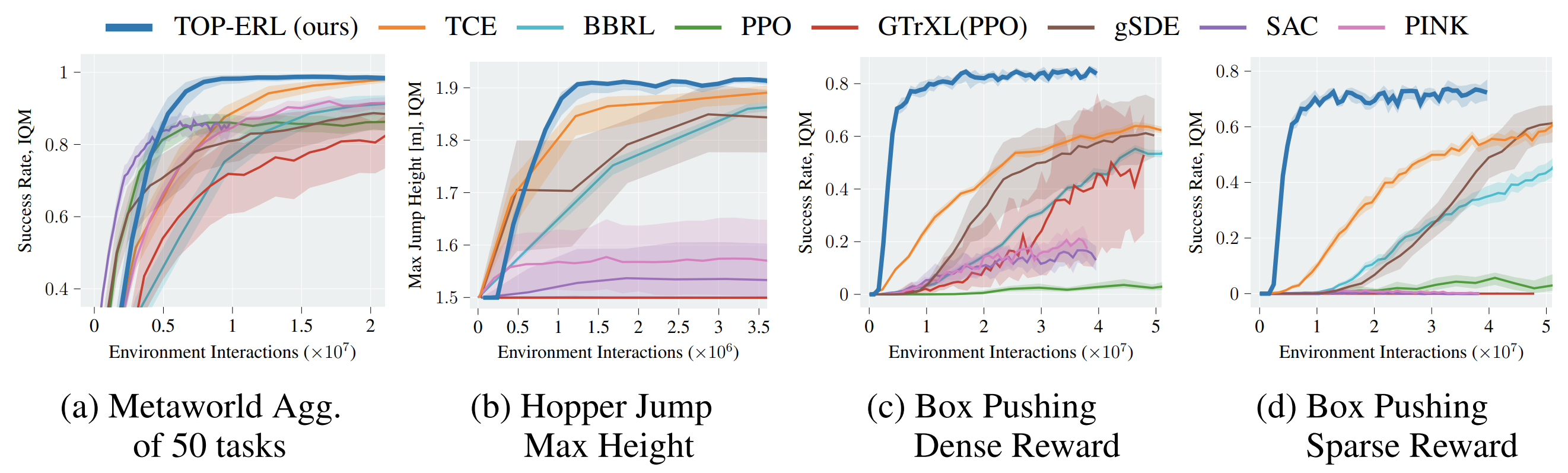
TOP-ERL: Transformer-based Off-Policy Episodic Reinforcement Learning
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, Gerhard Neumann, ICLR, 2025 Spotlight🔥 (top 5%).
See: Website | Code | OpenReview | arxiv
We propose a novel online off-policy RL methodology that utilizes a transformer-based critic to learn values of action sequences.

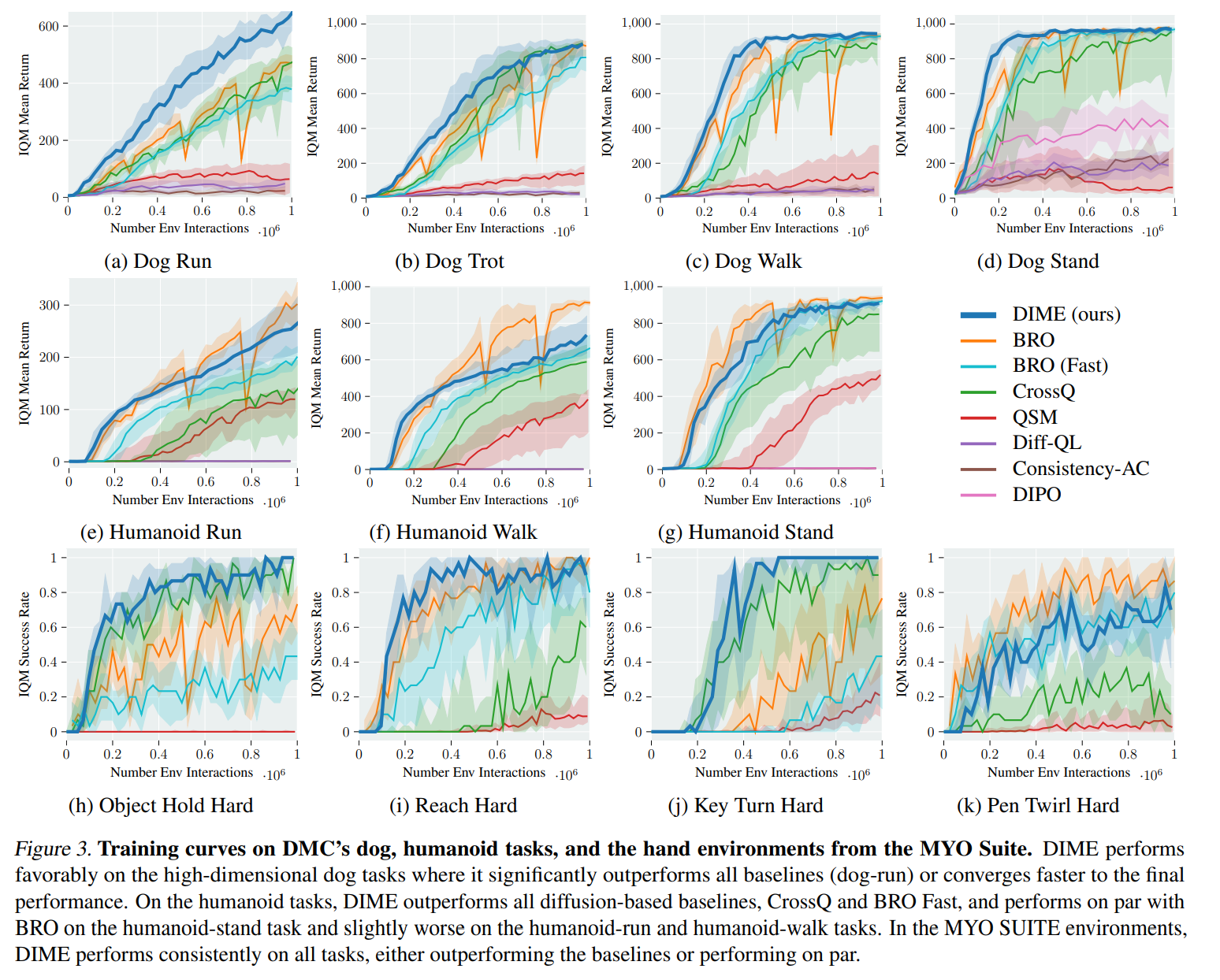
DIME: Diffusion-Based Maximum Entropy Reinforcement Learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, Gerhard Neumann, ICML, 2025.
See: Website | Code | OpenReview | arxiv
The SOTA diffusion-based online RL method that outperforms other cutting-edge diffusion and Gaussian policy methods.

BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Hongyi Zhou, Weiran Liao, Xi Huang, Yucheng Tang, Fabian Otto, Xiaogang Jia, Xinkai Jiang, Simon Hilber, Ge Li, Qian Wang, Ömer Erdinç Yağmurlu, Nils Blank, Moritz Reuss, Rudolf Lioutikov, NeurIPS, 2025.
See: arxiv
We present BEAST, a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-spline.
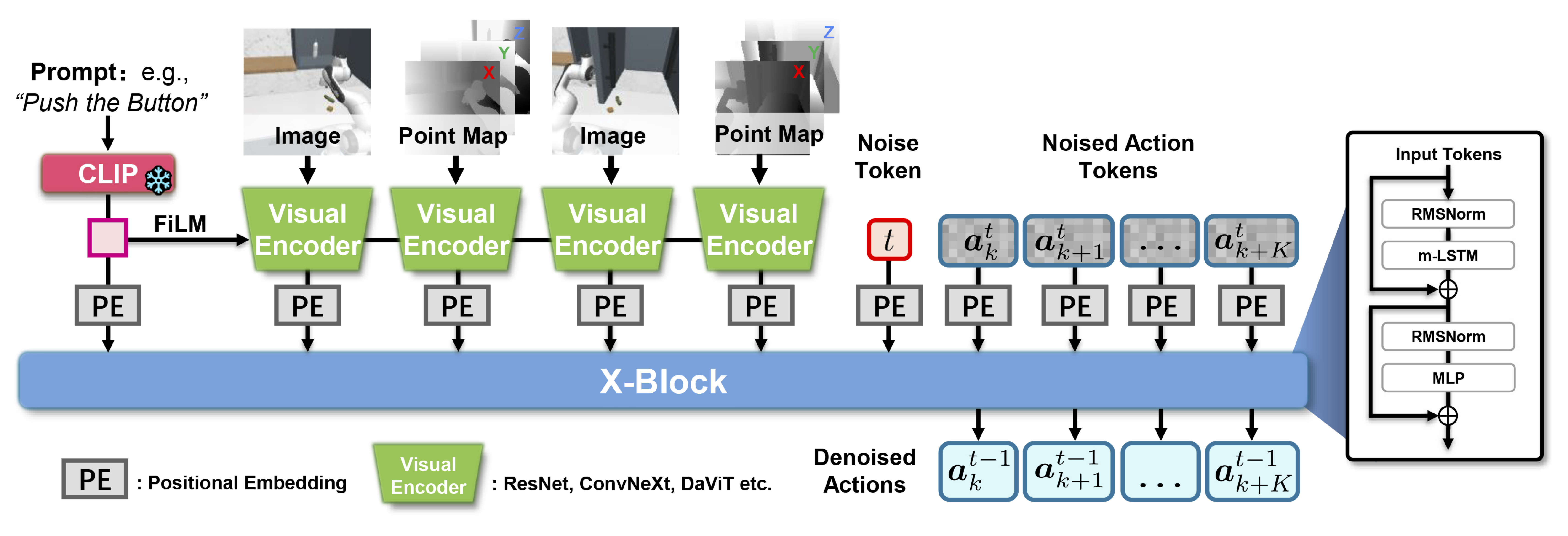
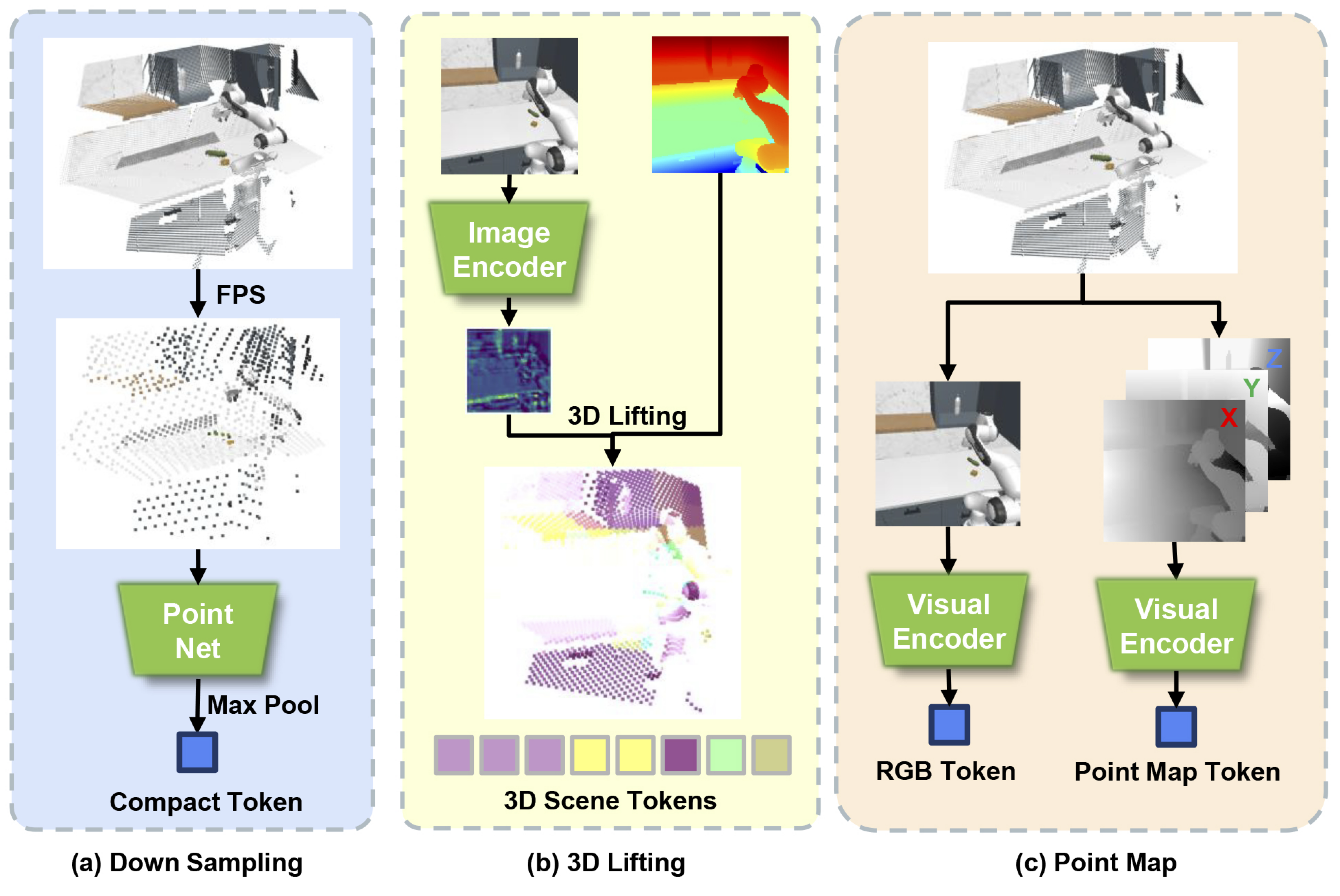
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Xiaogang Jia, Qian Wang, Anrui Wang, Han A. Wang, Balázs Gyenes, Emiliyan Gospodinov, Xinkai Jiang, Ge Li, Hongyi Zhou, Weiran Liao, Xi Huang, Maximilian Beck, Moritz Reuss, Rudolf Lioutikov, Gerhard Neumann, NeurIPS, 2025.
See: Website
We present PointMapPolicy, a multi-modal imitation learning method that conditions diffusion policies on point maps.


IRIS: An Immersive Robot Interaction System
Xinkai Jiang, Qihao Yuan, Enes Ulas Dincer, Hongyi Zhou, Ge Li, Xueyin Li, Julius Haag, Nicolas Schreiber, Kailai Li, Gerhard Neumann, Rudolf Lioutikov, CoRL, 2025.
We present IRIS, an immersive Robot Interaction System leveraging Extended Reality (XR), designed for robot data collection and interaction across multiple simulators, benchmarks, and real-world scenarios
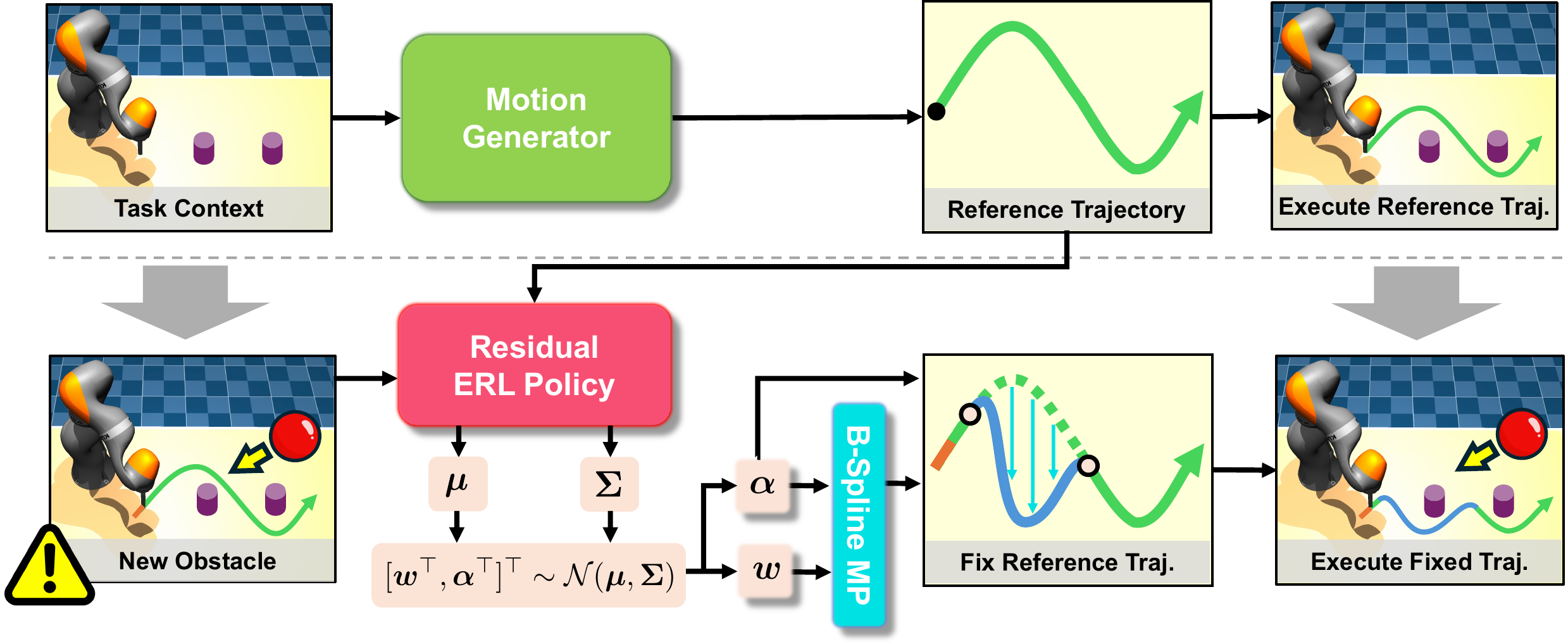

MoRe-ERL: Learning Motion Residuals using Episodic Reinforcement Learning
Xi Huang, Hongyi Zhou, Ge Li, Yucheng Tang, Weiran Liao, Björn Hein, Tamim Asfour, Rudolf Lioutikov, in IEEE Robotics and Automation Letters, RAL 2025.
See: arxiv
We propose MoRe-ERL, a framework that combines Episodic Reinforcement Learning (ERL) and residual learning, which refines preplanned reference trajectories into safe, feasible, and efficient task-specific trajectories.
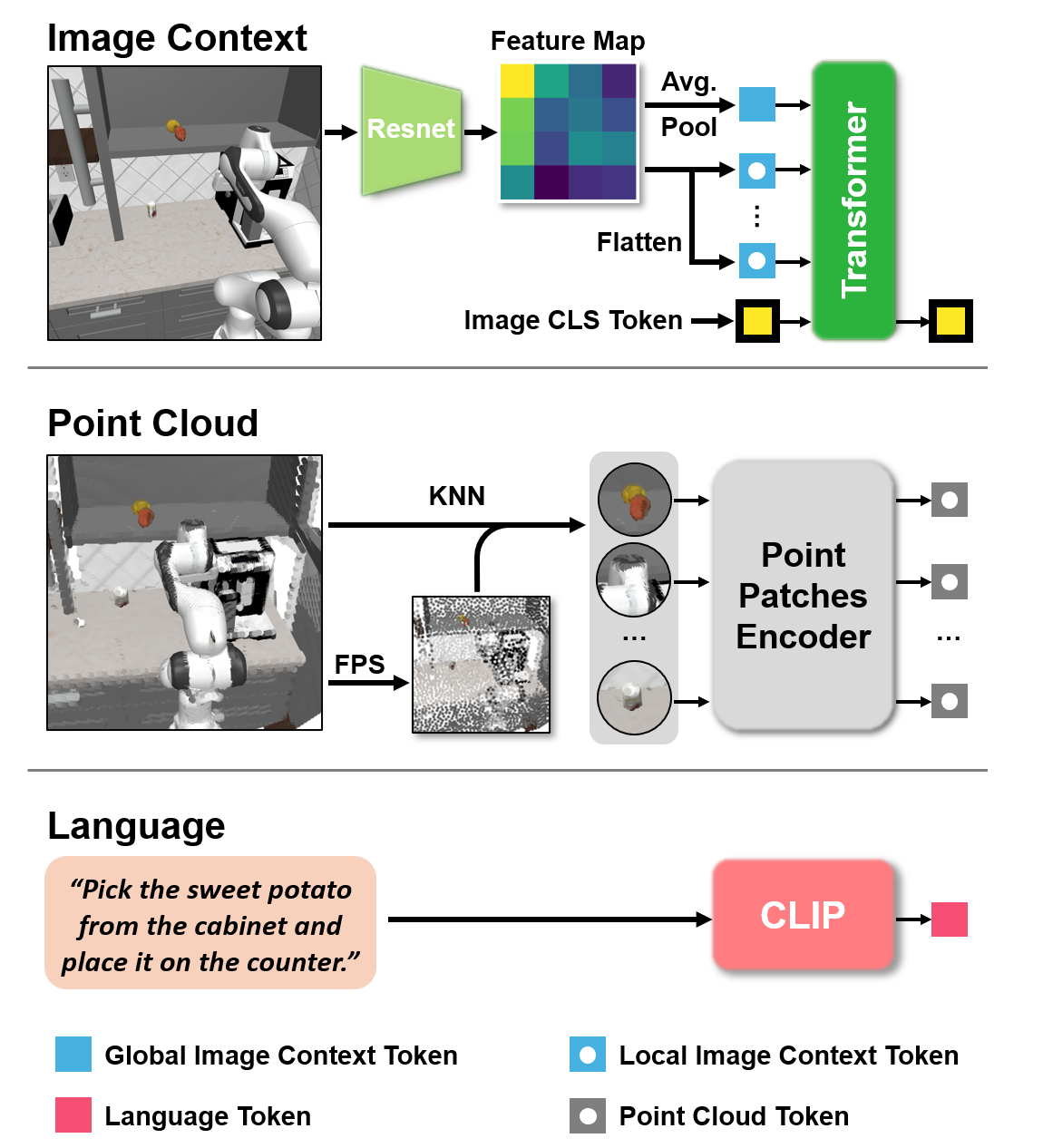
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Atalay Donat, Xiaogang Jia, Xi Huang, Aleksandar Taranovic, Denis Blessing, Ge Li, Hongyi Zhou, Hanyi Zhang, Rudolf Lioutikov, Gerhard Neumann, Preprint, 2025.
See: arxiv
We propose a novel imitation learning method that effectively fuses point clouds and RGB images by conditioning the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, preserving both geometric and contextual information and achieving state-of-the-art performance on the RoboCasa benchmark.
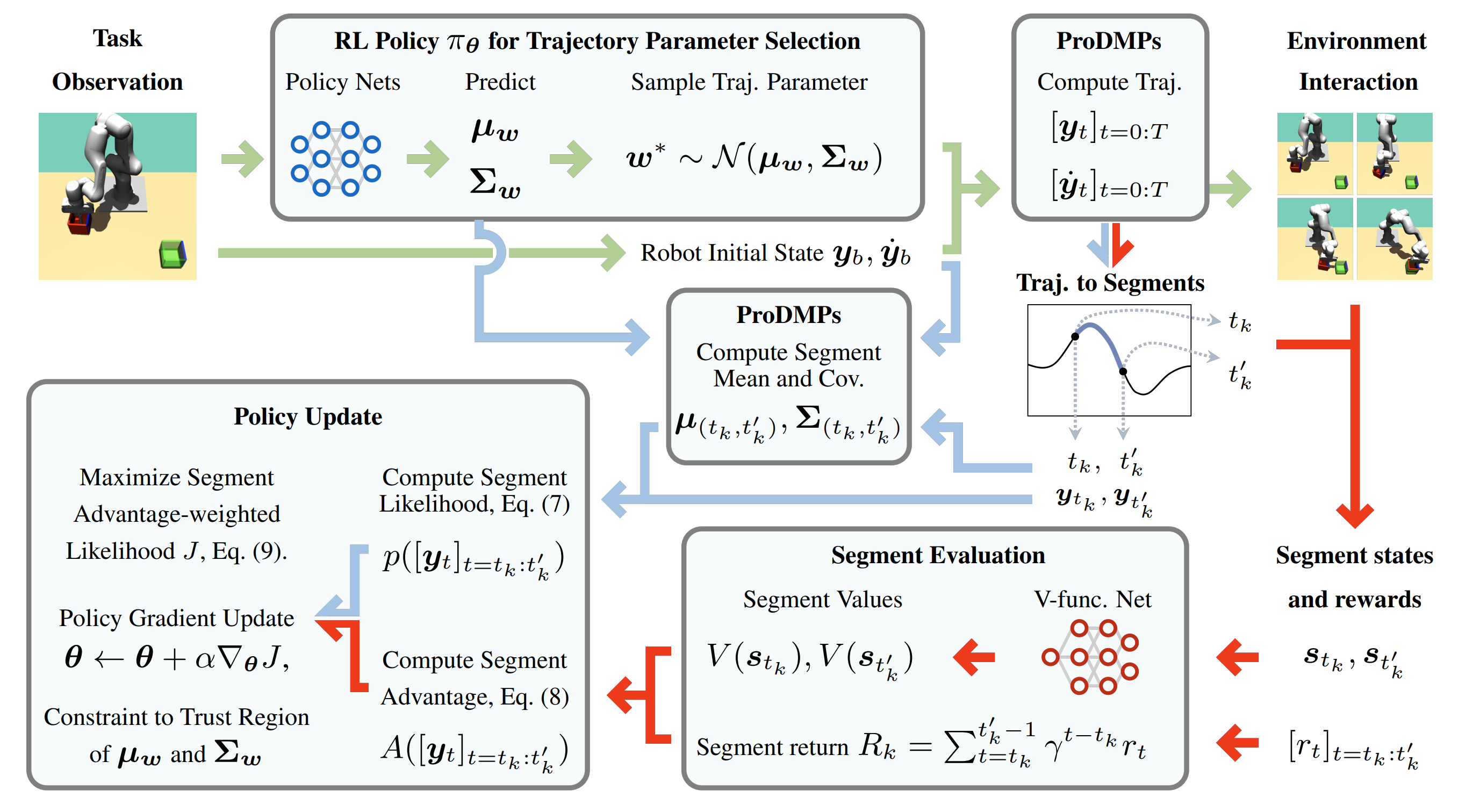
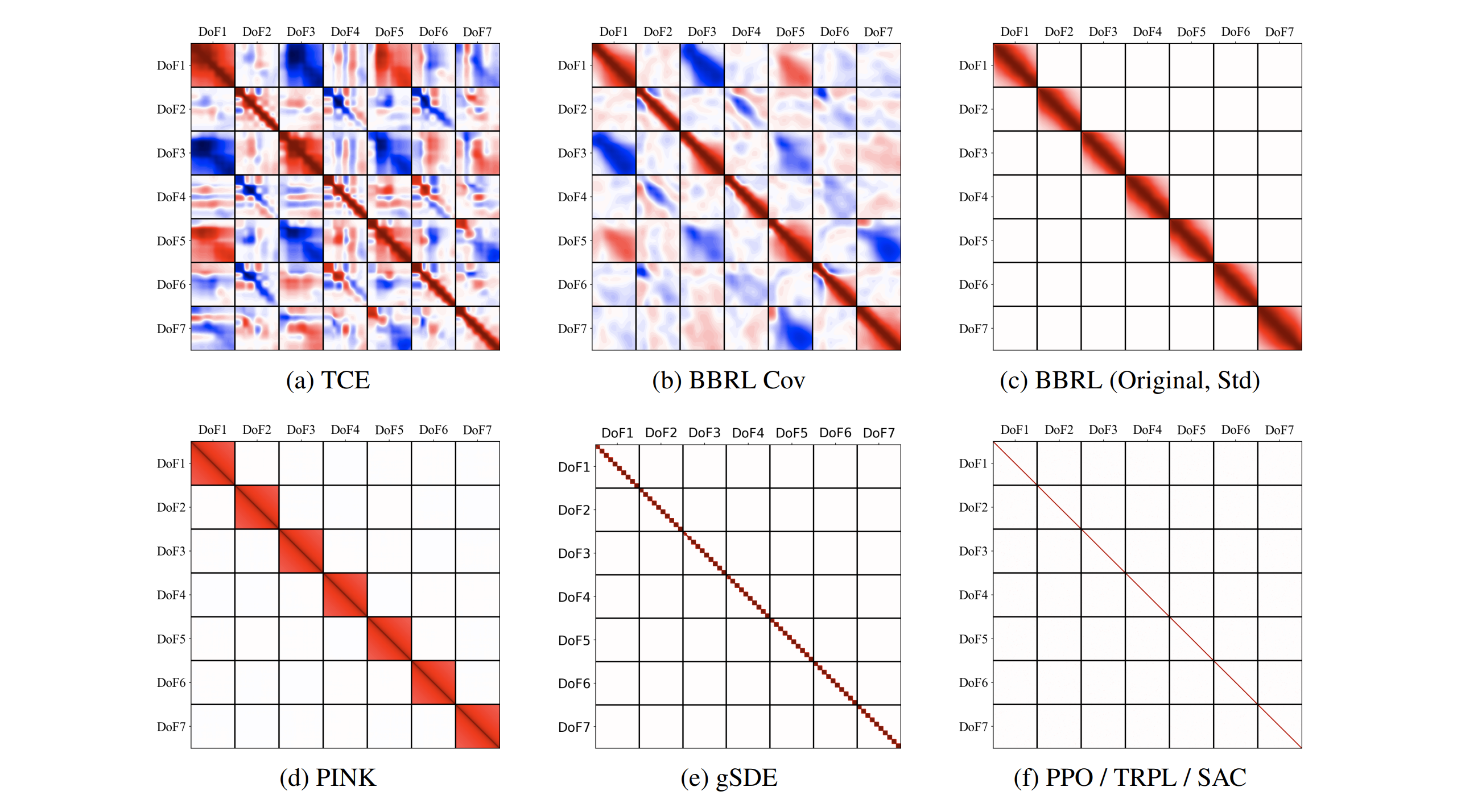
Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning.
Ge Li, Hongyi Zhou, Dominik Roth, Serge Thilges, Fabian Otto, Rudolf Lioutikov, Gerhard Neumann, ICLR, 2024.
See: arxiv | OpenReview | GitHub
We propose a novel RL framework that integrates step-based information into the policy updates of Episodic RL, while preserving the broad exploration scope, movement correlation modeling and trajectory smoothness.
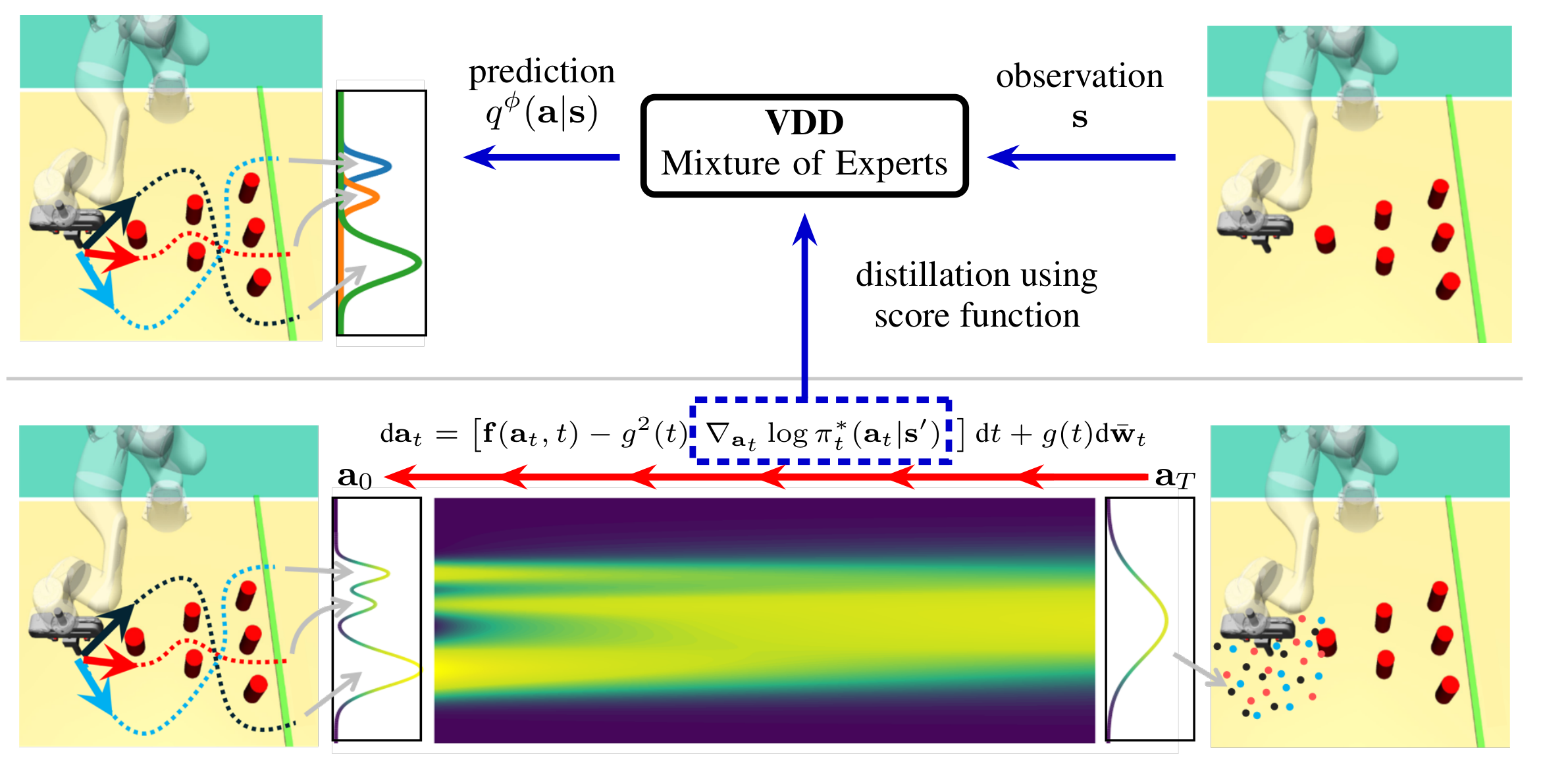


Variational Distillation of Diffusion Policies into Mixture of Experts
Hongyi Zhou, Denis Blessing, Ge Li, Onur Celik, Gerhard Neumann, Rudolf Lioutikov, NeurIPS, 2024.
We introduce Variational Diffusion Distillation (VDD), a novel method for distilling denoising diffusion policies into a Mixture of Experts (MoE).
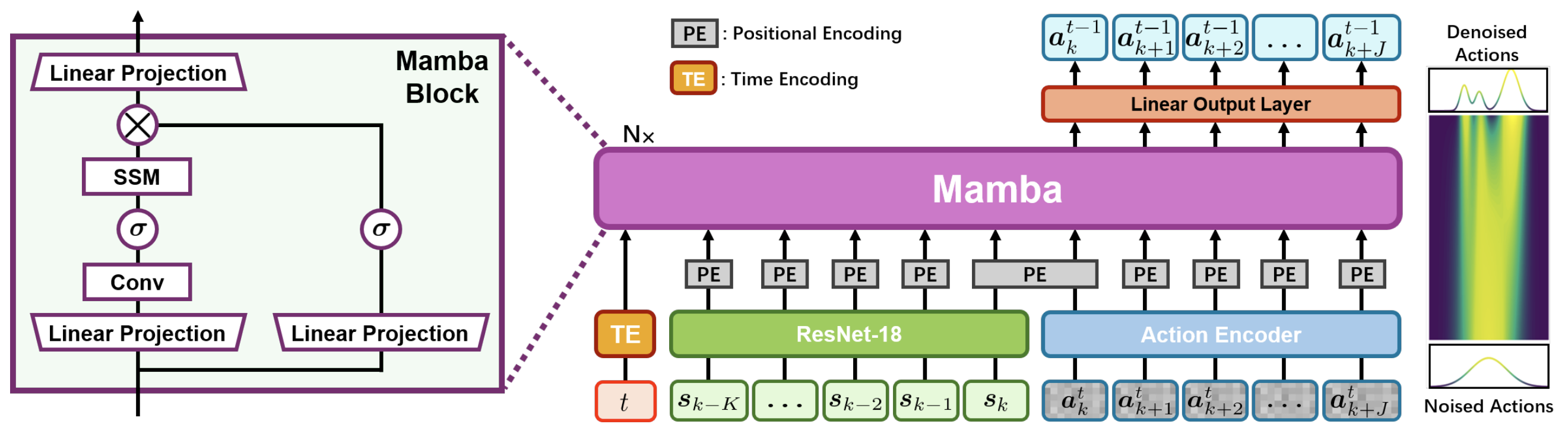



MaIL: Improving Imitation Learning with Selective State Space Models
Xiaogang Jia, Qian Wang, Atalay Donat, Bowen Xing, Ge Li, Hongyi Zhou, Onur Celik, Denis Blessing, Rudolf Lioutikov, Gerhard Neumann, CoRL, 2024.
See: arxiv | OpenReview | GitHub
We introduce Mamba Imitation Learning (MaIL), a novel imitation learning architecture that offers a computationally efficient alternative to state-of-the-art Transformer policies.
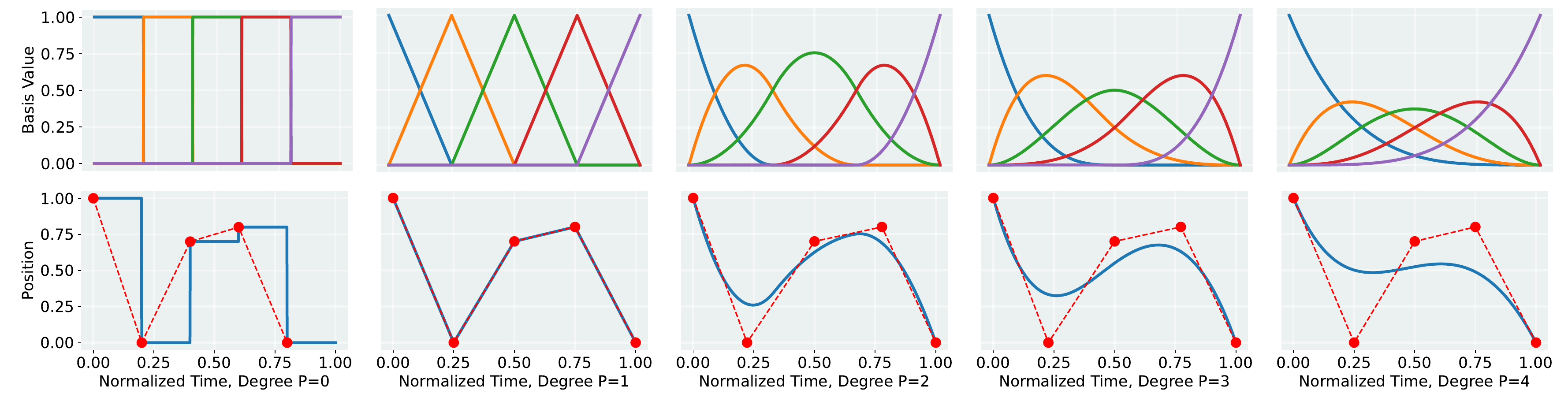
BMP: Bridging the Gap between B-Spline and Movement Primitives
Weiran Liao, Ge Li, Hongyi Zhou, Rudolf Lioutikov, Gerhard Neumann, in CoRL 2024 Workshop on Learning Effective Abstractions for Planning.
See: arxiv
This work introduces B-spline Movement Primitives (BMPs), a new Movement Primitive (MP) variant that leverages B-splines for motion representation.

MP3: Movement Primitive-Based (Re-) Planning Policies
Hongyi Zhou, Fabian Otto, Onur Celik, Ge Li, Rudolf Lioutikov, Gerhard Neumann, in CoRL 2023 Workshop on Learning Effective Abstractions for Planning.
We enable a new Episodic RL framework that allows trajectory replanning in deep RL, which allows the agent to react with changing goal and dynamic perturbation.

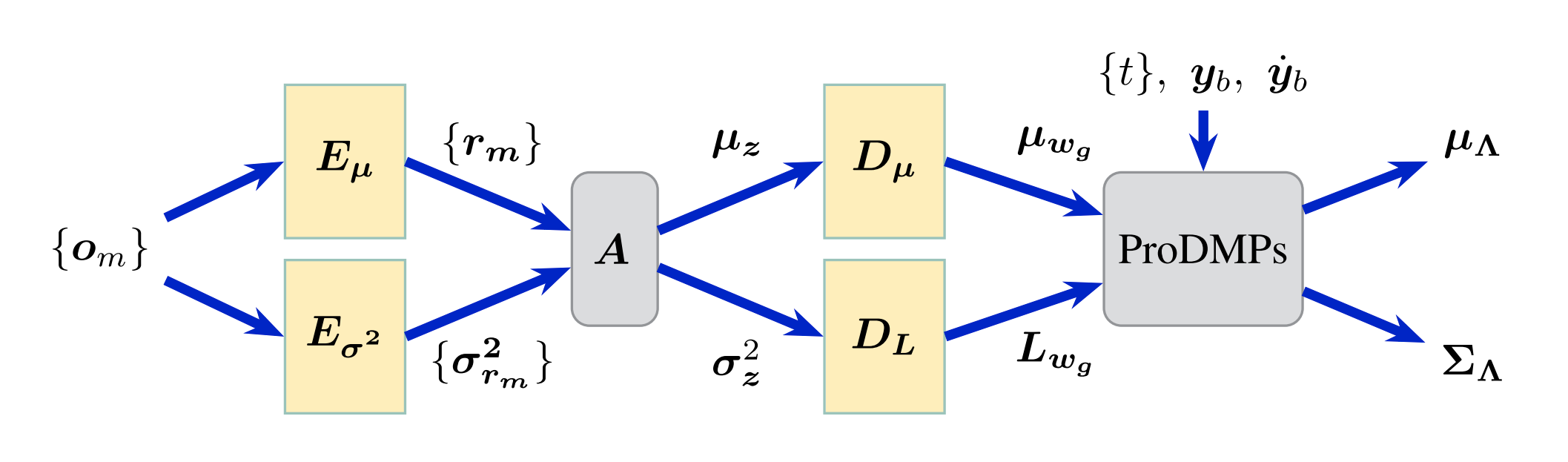
ProDMPs: A Unified Perspective on Dynamic and Probabilistic Movement Primitives.
Ge Li, Zeqi Jin, Michael Volpp, Fabian Otto, Rudolf Lioutikov and Gerhard Neumann, in IEEE Robotics and Automation Letters, RAL 2023.
See: Paper | Poster | GitHub | YouTube
We unified the Dynamic Movement Primitives and the Probabilistic Movement Primitives into one model, and achieved smooth trajectory generation, goal-attractor convergence, correlation analysis, non-linear conditioning, and online re-planing in one framework.
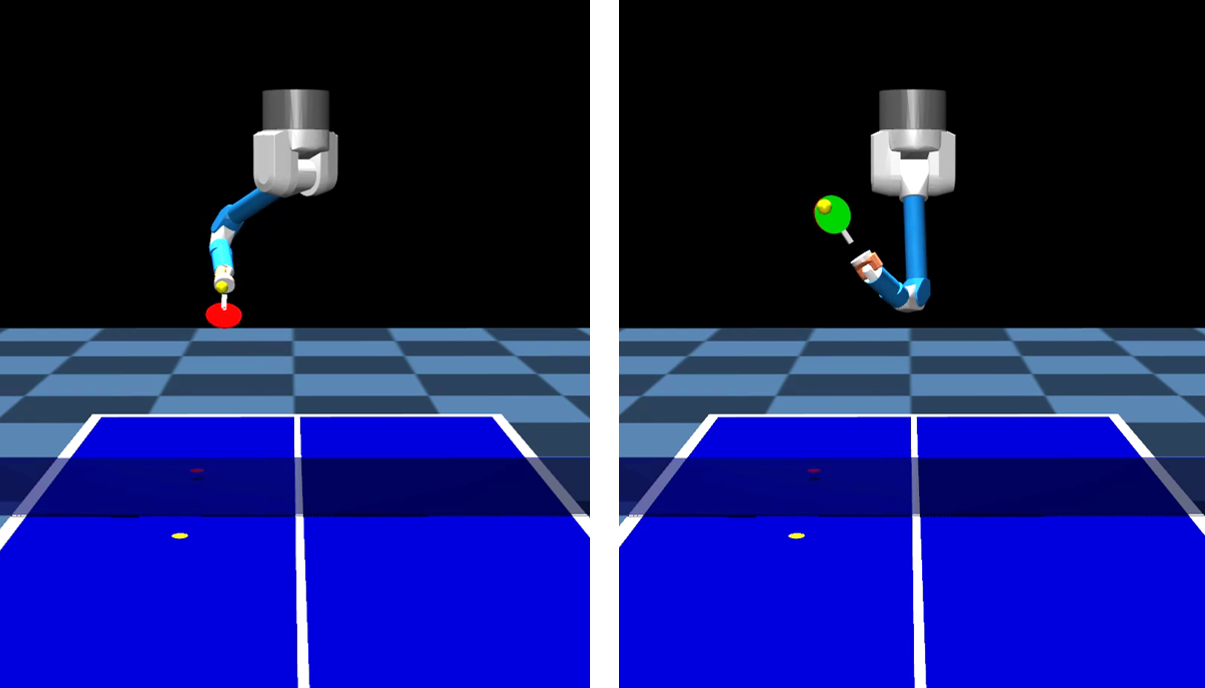
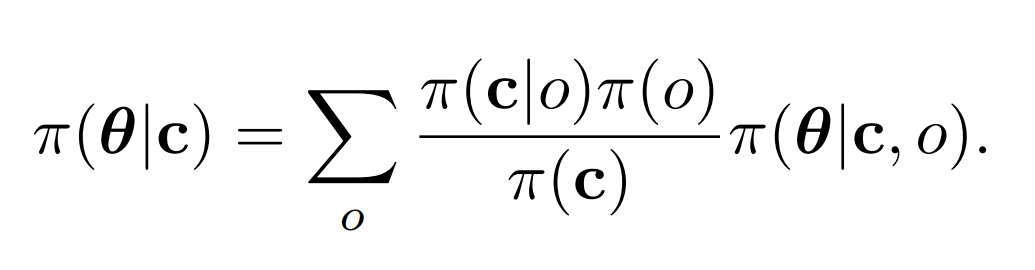
Specializing Versatile Skill Libraries using Local Mixture of Experts
Onur Celik, Dongzhuoran Zhou, Ge Li, Philipp Becker, Gerhard Neumann, in Conference on Robot Learning, CoRL 2021.
See: Paper | OpenReview | YouTube
We developed a mixture of experts RL framework to learn versatile skills given the same task, such as forehand and backhand strikes in playing table tennis. Our method is able to assign policy experts to their corresponding context domains and automatically add or delete these experts when necessary.